
[ad_1]
Very last 12 months, I wrote listed here about the beta launch by Casetext of a strong research instrument, WeSearch, produced applying an rising branch of synthetic intelligence acknowledged as neural networks, that is remarkably adept at locating conceptually similar documents, even when they have no matching search phrases.
Now, Casetext is formally launching that lookup resource less than a new name, AllSearch, and with a emphasis on encouraging litigators lookup substantial sets of authorized documents, together with for e-discovery or to research inner databases and repositories, this kind of as brief banks, litigation records, deposition transcripts, and expert reviews.
It is now also completely integrated with the Casetext legal investigate platform, so that a consumer can at the same time search key and secondary authorized means and their very own doc collections.
“I see this as the most critical solution launch in the historical past of the enterprise by far,” Pablo Arredondo, Casetext’s cofounder and chief innovation officer, advised me for the duration of a demonstration of AllSearch, “because I believe it signifies our ability to extend effectively further than lawful analysis and to provide all that Casetext is to all the other oceans of information out there that require it.”
Neural Community Framework
Just before I say far more about this new product, make it possible for me to provide some history.
As I explained in that submit previous year, in 2020, Casetext launched Compose, a 1st-of-its-variety products that helps legal professionals build the initial draft of a litigation temporary in a portion of the time it would generally get.
A core component of Compose was Parallel Research, a potent software for locating conceptually similar circumstances, even when they incorporate no matching keywords. As I wrote in yet another submit, Parallel Lookup could be regarded the magic formula sauce of Compose, employing an advanced neural network-primarily based technique to to adhere to you as you draft a transient and routinely offer you with conceptually pertinent precedent.
What is impressive about Parallel Research is its skill to go outside of the kinds of results you would expect from key word browsing, discovering conceptually analogous caselaw even when the conditions do not use the same language.
As Arredondo places it, when compared to Parallel Search, “what many others named purely natural language lookup was just everyday Fridays in the search phrase prison.”
(I present some examples of the power of Parallel Look for in this prior publish.)
It is primarily based on transformer-dependent neural networks, the very same typical technique that underpinned Google’s open up-source network framework made by Google referred to as Bidirectional Encoder Representations from Transformers, or only BERT. Casetext customized the strategy to make it function on the nuance and scale that litigation necessitates.
Evidence of Notion
When Casetext released WeSearch, it took that power of Parallel Look for and extended it to nearly any collection of documents on which you may want to unleash it.
But it initially released the product in beta only to select firms as a type of evidence of idea that this technological innovation could be extended past case legislation to other styles of document sets.
“The beta has been a really highly effective validation for us of how this edge of how you capture language — this capability to look for by principle, not literal keywords and phrases — truly can be applied effectively anywhere that lawyers are owning to navigate a lot of language, a lot of files, loads of textual content,” Arredondo reported.
Amid the beta people have been substantial corporations that have used it in substantial-stakes e-discovery, and that have reported back again to Casetext that they have been able to obtain important proof a lot before in the litigation.
Companies in the beta have also applied it to look for quick financial institutions, transcripts, litigation data files, SEC paperwork, contracts, and a lot more, Arredondo mentioned. Beta testers also integrated smaller and boutique companies, that utilised it to look for by means of a entire litigation history or to approach documents been given through an FOIA request.
Now Entirely Built-in
With this whole professional launch, AllSearch is now absolutely built-in within Casetext and appears as on solution on the site’s house site. Customers can upload any doc set that they want to look for, and can generate many databases of documents. For incredibly-huge doc sets, a Casetext concierge can assistance with the add.
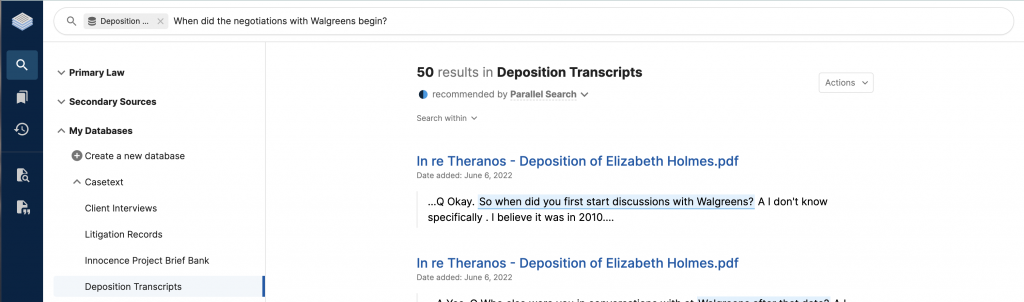
End users can look for the two their very own databases and lawful resources, either at the same time or selectively.
The major established a agency has uploaded so far consisted of some 2 million paperwork.
People can look for any one of their uploaded databases, across many, or across both equally authorized investigation sources and uploaded databases.
The value for this will change with the subscription sort, but will be based on per-gigabyte storage. Business buyers will have custom preparations with Casetext, whilst more compact business users will have a approach that starts with a gigabyte of storage.
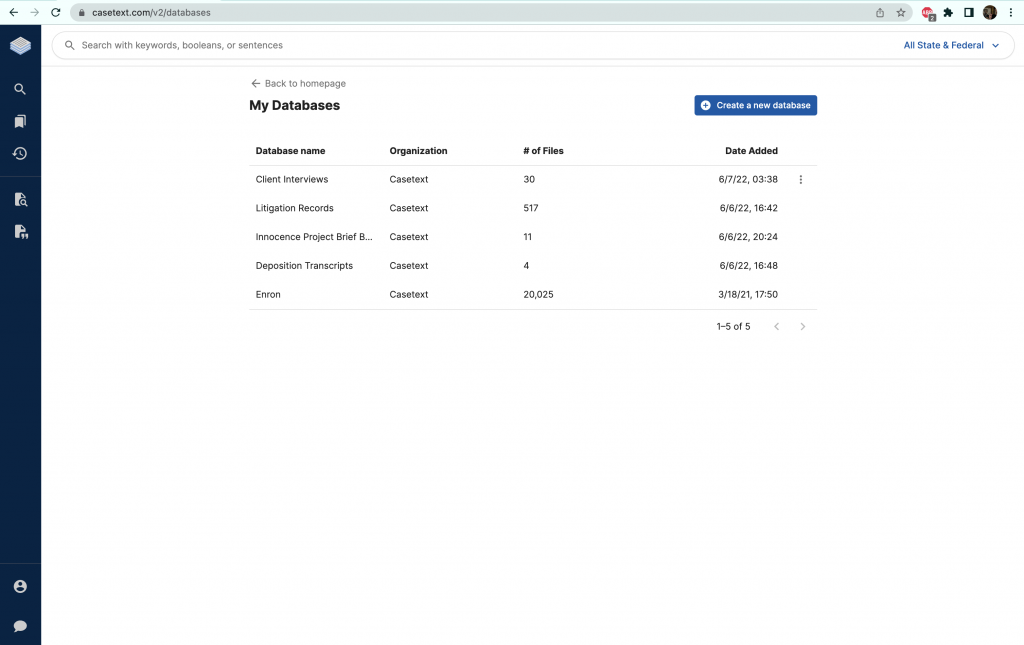
End users can upload any document established to look for.
Even though I beforehand analyzed WeSearch, I have not yet had the opportunity to exam this new release, which Arredondo claimed has been even more refined for even extra specific research success. I approach to exam it shortly and will post a comply with-up when I do.
For Casetext, Arredondo sees this start as the upcoming step in the company’s evolution, to providing an integrated procedure, driven by AI, exactly where lawyers have obtain to anything they want.
“What we’re seriously energized about is acquiring all of the important info that an legal professional requires in one particular region, and then implementing the complete slicing edge AI to it,” he reported.
“For us at Casetext, that’s exactly where we see ourselves going now, as being the finest business to use artificial intelligence to the total details ecosystem, if you will, that a attorney demands to do the job in.”
[ad_2]
Supply url




More Stories
Will a review of Iran’s hijab law stop the protests? – HotAir
The Importance of How You Announce Your Company’s M&A Deal – KJK
Iran’s morality police dissolved, says prosecutor general